Resources for repliCATS participants
Version: last updated on 7 March 2024
If you are looking for the resources for Unimelb first year psych, you need to click here (Canvas login required).
—
On this page, you can find information about:
- Structured expert elicitation with the IDEA protocol
- Answering the review questions
- The repliCATS Code of Conduct
Structured expert elicitation with the IDEA protocol
The repliCATS approach is based on a type of Delphi protocol called IDEA.
IDEA stands for “Investigate”, “Discuss”, “Estimate” and “Aggregate”, the four steps in this structured elicitation process.
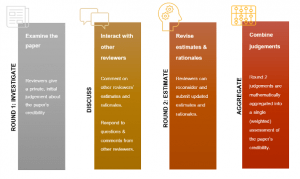
As used in the repliCATS project, the IDEA protocol asks participants/reviewers to:
- Independently Investigate the paper, providing their personal judgement on multiple credibility dimensions of the central claim, and commenting on their thinking. Reviewers will be asked to give a quantitative assessment for each dimension and – for some questions – indicate their confidence using lower and upper bound estimates.
- Engage in an online (asynchronous) Discussion with other reviewers of the same paper. Upon submitting their initial judgements, reviewers will be able to see the anonymised estimates as well as the aggregated judgement across all reviewers. At this point, reviewers can also comment on others’ assessments and their written rationales. This phase is intended to help resolve uncertainties and allow reviewers to investigate the strength of the evidence for and against certain judgements.
- Submit a revised quantitative Estimate for each of the credibility dimensions and describe how their thinking has changed.
The repliCATS team will compute an Aggregate of the group judgements which comprises the final assessment of the paper’s overall credibility.
More information on the IDEA protocol can be found here.
The repliCATS platform
Logging on
First, you will need to create an account. You will need a valid email address to proceed, and you will be asked to review the Plain Language Statement outlining the aims and objectives of the study, and consent to participating in this study.
Once your account is activated (this should be immediate), your username will be your email address. On the platform, you will be identified only by your avatar (e.g., Echidna_231).
How to use the platform
We have created a quick video that takes you through the key features of the platform.
Answering the questions
You will be asked to provide a quantitative estimate on 8 credibility dimensions, using either a 0-100 point estimate, or a probability estimate with a lower and upper bound. Please outline your reasoning for each of the judgments in the comments box for Q8: Credibility. Use the question navigation panel to skip between entering estimates for the various questions and the Q8 text box.
The 8 credibility dimensions
Please click on the credibility dimensions below to learn more about the relevant review question, its purpose and to access detailed guidance on how to answer it.
Question: How well do you understand the paper overall?
Purpose: To understand if anything affects your ability to interpret the paper and identify its central claim(s).
Clarification: We know that scientific papers vary in clarity and comprehensibility. It’s possible that a paper:
- is vague;
- is poorly written;
- relies on an unfamiliar procedure;
- contains too much jargon;
- is unclear about exactly what the central claim is;
- is about a concept that you are not familiar with and/or have difficulty conceptualising.
These factors can all contribute to your ability to be able to interpret the paper and may in turn lead to different interpretations by different reviewers. There is a comments box below this question, where you can provide a summary of the paper’s central claim, as you see it. We would like you to focus on the higher-level finding (the ‘take-home message’, if you will), not detailed results. There will be space to consider individual results later. Sharing your interpretation will help highlight whether there are different possible interpretations of the paper’s central claim(s).
Answering the comprehensibility question:
We’re asking for this on a scale of 0 to 100. 0 means that you have no idea what the paper means, 100 means it’s perfectly clear to you. This is inherently a subjective measure, aimed at getting an overall sense of how clear it was to you, given your reading of it, and you knowledge and background.
Some papers may be outside of your core area of expertise or use unfamiliar terminology. This should not automatically lead to a low score, however, if after completing your reading of the paper, you are no clearer about the central claim(s), you should indicate this to is in the text box and consider whether this is a reflection of the quality of the research being described in this paper.
Comments box: Try to rephrase what you think the paper is about and what the central claim(s) is/are. This may be useful in Round 2 when you might want to compare your initial interpretation of the paper to that of other reviewers. Please reserve more detailed considerations about the paper’s credibility or overall quality for the comments box after Q8.
Question: What’s your initial reaction: is the underlying effect or relationship plausible?
Purpose: To capture your prior beliefs about whether the underlying effect or relationship corresponds to something real.
Clarification: We’ve included this question here to allow you to state your prior belief about whether or not the central claim(s) represent(s) a true phenomenon, regardless of what you think about this particular study design.
Answering the plausibility question:
We’re asking for this on a scale of 0 to 100. 0 means that the paper is exactly contrary to your pre-existing beliefs, 100 means it’s perfectly compatible with them.
The word ‘plausible’ means different things to different people. For some people, almost everything is ‘plausible’, while other people have a stricter interpretation. Don’t be too focused on the precise meaning of ‘plausible’ – you could also consider words like ‘possible’ or ‘realistic’ here.
Question: Do the authors share all the information necessary about the methods, analyses and procedures that would allow someone else (not involved in the original research) to evaluate or replicate the research in this paper?
Purpose: To gauge your assessment on the quality and clarity, and accuracy of reporting in the paper
Clarification: Transparency in this context refers to a clear, unambiguous description of the methods used in the research, including experimental procedures, materials, tests and analytical techniques. Consider how easy it is to find all of the information required to perform a close replication of the study. This includes whether or not the study was pre-registered.
Answering the transparency question:
We’re asking for this on a scale of 0 to 100. 0 means that the paper is very unclear, not at all transparent in its methods, procedures and/or analyses, 100 means it’s perfectly clear and transparent, to the point that another researcher would be able to repeat the methods, procedures and analyses without issue.
Question: What is the probability (0-100%) that a close replication of the central claim, conducted by an independent researcher, would find results consistent with the original paper?
Purpose: The question is asking about a close replication of the central claim of the paper. However, you may also consider the average replicability of several different claims made in the paper, e.g. when the central claim is not clear.
Clarification: A close replication is a new study that follows the methods of the original with a high degree of similarity, varying only aspects that are – based on best available judgment – not relevant to the central claim. People often use the term direct replication – however, no replication is perfectly direct, and we cannot describe precisely how any given claim might be replicated. Our best advice is to imagine what kinds of decisions you would face if you were asked to replicate this study, and then to consider the effects of making different choices for these decisions.
A successful replication consistent with the original paper is one that finds a statistically significant effect (defined with an alpha of 0.05) in the same direction as the original study, using the same statistical technique as the original study.
Specifically, for close replications involving new data collection, we would like you to imagine 100 (hypothetical) new replications of the original study, combined to produce a single, overall replication estimate (i.e., a good-faith meta-analysis with no publication bias). Assume that all such studies have both a sample size that is at least as large as the original study and high power (90% power to detect an effect 50-75% of the original effect size with alpha=0.05, two-sided).
Sometimes it is clear that a close replication involving new data collection is impossible, or infeasible. In these cases, you should think of data analytic replications, in which the central claim is tested against another pre-existing dataset that provides a fair test. Again, imagine 100 datasets analysed with results are combined to produce a single, overall replication estimate.
You should assume that any such replications are conducted competently and in good faith.
Answering the replicability question:
For replicability, we ask you to provide a lower bound, upper bound and best estimate (for further details see: The three-step response format. In making these determinations, consider all the reasons why the central claim may or may not replicate. We understand that your thoughts about the prior plausibility of this claim are likely to influence your judgement regarding this question. However, we’d like you to try and think more critically of other reasons why this particular study may (or may not) replicate. In answering this question, please only use whole integers – do not use decimal places.
Additional considerations on the question of replicability:
There are many things you might consider when making your judgement. The IDEA protocol operates well when a diversity of approaches is combined. There is no single ‘correct’ checklist of parameters to assess. However, some factors you may wish to consider include:
- The statistical data, analyses and results reported within the paper, including sample size, effect size and p-value, if reported. These details are likely to be important for whether a claim replicates.
- The study design. Will it be reliable in replication? Are there any signs of Questionable Research Practices, e.g. unusual designs where more straightforward tests might have been run but failed? Note that this question is interested in the replicability of the central claim even if the external validity of the design is low.
- Your prior plausibility for the paper. Background probabilities are often a major factor. Is this area of research more or less well-understood?
- Contextual information about the original study or publication such as where and when the paper was published, and who undertook the original study. Do you have any private or personal knowledge e.g. experience with undertaking similar research, or existing knowledge about the quality of work from a particular source?
Question: Imagine an independent analyst receives the original data and devises their own analyses to investigate the central claim of this paper. What is the probability (0-100%) that an alternative analysis would find results consistent with the original paper?
Purpose: To capture your beliefs about the analytic robustness of the main finding.
Clarification: The term robustness is used here to represent the stability and reliability of a research finding, given the data. It might help to think about it in this way: imagine 100 analysts received the original data and devised their own means of investigating the central claim (e.g using a different, but entirely appropriate statistical model or technique), how many would find a statistically significant effect (defined with and alpha of 0.05) in the same direction as the original finding?
You should assume that any such analyses are conducted competently and in good faith.
Answering the robustness question:
Like Q4: Replicability, we ask you to provide a lower bound, upper bound and best estimate. In making these determinations, consider all the reasons why another researcher using a different analytic approach on the original data might find a result that is (not) consistent with the original claim, and provide your best estimate on the balance of the evidence.
This question has two parts, asking you to give an overall rating, and identify the features of the study that affect its generalizability.
Question 6a: Going beyond close replications and reanalyses, how well would the main findings of this paper generalize to other ways of researching this question?
Purpose: To assess whether the main claim(s) of the paper would hold up under different ways of studying the question.
Clarification: This question is asking about generalizations of the original study or ‘conceptual replications’. We want you to consider generalizations across all relevant features, such as the particular instruments or measures used, the sample or population studied, and the time and place of the study.
Answering the generalizability rating question:
This question is asked on a scale of 0 to 100, where 0 means the central claim is not at all generalizable and 100 means it is completely generalizable.
We know that there are many different features of a given study that potentially limit generalizability, and they may have different levels of concern, so it might be unintuitive to provide a single rating across all of them. You might want to imagine 100 (hypothetical) conceptual replications of the original study, each of which varies just one specific aspect of the study design (e.g. sample, location, operationalisation of a variable of interest,…) while holding everything else constant. Across this hypothetical set of conceptual replications, all relevant aspects of the study are varied in turn. How many of these do you estimate would produce a finding that is consistent with the finding in the original study?
Question 6b: Please select the feature(s), if any, that you think limit the generalizability of the findings.
Purpose: To capture study features that raise substantial generalizability concerns.
Clarification: Select the features for which you definitely have generalizability concerns. Don’t select a feature if you simply think that it is possible that the study will not generalize over that feature.
Answering the generalizability features question:
Please select all features you think raise substantial generalizability concerns. If there is a feature that we have not listed that you think raises substantial generalizability concerns, then select ‘Other’ and briefly describe the feature in the text box. Please do not use this text box to discuss why you think there are generalizability concerns. If you have any comments or thoughts on this, please log write them in the comments box for Question 8: Credibility.
This question has three parts, asking you to assess the appropriateness of the study design, the analytical approach and the conclusions.
Question 7a: How well-designed is the research presented in this paper to address its aims?
Purpose: To judge the degree to which the conclusions of the study can be inferred from the reported effect, given the study design.
Clarification: This question focuses on internal validity, or the extent to which the study measures what it aims and claims to measure. That is, are the chosen methods suited to address the research aim(s)? In a well-designed study, systematic errors and bias can be discounted, such that the outcome can be reliably linked to the (experimental) manipulation or variable of interest. For example, claims about causal relationships among variables need to be warranted by the evidence reported.
Answering the design validity question:
We’re asking for this on a scale of 0 to 100. 0 means that the study design is not at all suited to address the research aim(s), 100 means it’s perfectly suited to address the research aim(s).
Question 7b: How appropriate are the statistical tests in this paper?
Purpose: To judge the extent to which a set of statistical inferences, and their underlying assumptions, are appropriate and justified, given the research hypotheses and the (type of) data.
Clarification: This question focuses on a different aspect of internal validity, namely on the extent to which the statistical models/tests are appropriate for testing the research hypotheses. For instance, assumptions may have been violated that would render the chosen test(s) inappropriate, or the statistical model of choice may not be appropriate for the type of data.
Answering the analytic validity question:
We’re asking for this on a scale of 0 to 100. 0 means that the statistical analyses are not at all appropriate to test the research hypotheses, 100 means they are entirely appropriate to test the research hypotheses.
Question 7c: How reasonable and well-calibrated are the conclusions drawn from the findings in this paper?
Purpose: To judge the extent to which the paper’s conclusions are warranted, given the findings.
Clarification: This question relates to the stated interpretation of the findings, that is, whether the conclusions match the evidence presented, given the limitations of the study. Sometimes a paper’s conclusion(s) might extend beyond what is indicated by the results reported.
Answering the conclusion validity question:
We’re asking for this on a scale of 0 to 100. 0 means that the conclusion is unrelated to the evidence presented, 100 means the conclusion perfectly represents the evidence presented.
Question: How would you score the credibility of this paper, overall?
Purpose: This question allows you to express your judgement on the overall credibility of the paper, incorporating all of the dimensions that we have asked about so far (Q1-7), as well as any other factors you think may be relevant.
Clarification: We have intentionally not specified an exact interpretation or definition of the concept of ‘credibility’. We want you to determine what you think is credible.
Answering the paper credibility question:
We ask you to provide a lower bound, upper bound and best estimate. In making these determinations, you should consider all the previous dimensions and any additional information that you deem pertinent to the paper’s credibility.
Different reviewers may have different mental models of ‘credibility’. There is no one right way of thinking about this. You might want to think about how likely you would be to use this paper, if you were working in the same field, or how likely you would be to apply the finding(s) presented in the paper when making policy (or other) decisions. However, you might have other ways of thinking about it. You may wish to just average across all of the credibility dimensions we have asked you to assess (e.g. plausibility, replicability,…). Some dimensions may be more important than others and you may want give those dimensions more weight in your aggregate assessment. We also may have failed to ask about something that you think is important for this paper, so you might include additional or completely different factors in your judgement about credibility for that paper.
If you are able to describe how you have thought about overall credibility, please do so in the comments box.
Providing a rationale
Please use the text box linked to Question 8 (Credibility) to capture all of your thinking and reasoning about the credibility assessments of this paper.
Note that you can navigate to this text box at any stage of your review, so you can drop comments in as you go through the 7 specific dimensions of credibility.
Collecting all of your reasoning in this one spot allows us to understand how you assessed the paper, which factors were important and which were less influential in determining your judgement about the credibility of this paper. Please be as comprehensive as you can as it will provide valuable context during Round 2 of the review process when all reviewers will be able to see and evaluate each others’ (anonymous) estimates and comments.
In the text box, please do not use your own name or the name of any other reviewer or any other distinguishing remark such as your affiliation or your professional position. While the reviews will eventually be published, at this stage in the process it is important that comments are not attributable to specific people, as we want reviewers to evaluate them at face value.
The three-step response format
Questions 4,5 and 8 ask you to provide three separate estimates: a lower bound, upper bound and best estimate. We will illustrate this approach using Question 4: Replicability as an example. Think about your assessments of Question 5: Robustness and Question 8: Credibility in a similar manner.
There is good evidence that asking you to consider your lower and upper bounds before making your best estimate improves the accuracy of your best estimate. The difference between your upper and lower estimates is intended to reflect your uncertainty about whether the central claim(s) would replicate. Wide intervals should signal greater uncertainty.
- First, consider all the possible reasons why the central claim of the paper is unlikely to successfully replicate. Use these to provide your estimate of the lowest probability of replication.
- Second, consider all the possible reasons why a claim is likely to successfully replicate. Use these to provide an estimate of the highest probability of replication.
- Third, consider the balance of evidence. Provide your best estimate of the probability that a study will successfully replicate, somewhere between your lower and upper bound – the interval does not have to be symmetrical around the best estimate.
Some additional considerations on the three-step format:
- Providing a lower estimate of 0 means you believe a study would never successfully replicate, not even by chance (i.e. you are certain it will not replicate). Providing an upper estimate of 100 means you believe a study would never fail to replicate, not even by chance (i.e. you are certain it will replicate).
- Providing an estimate of 50 means that you believe the weight of evidence is such that it is as likely as not that a study will successfully replicate. If you have low prior knowledge and/or large uncertainty, please use the width of your bounds to reflect this, and still provide your best estimate of the probability of replication.
- Any answer above 50 indicates that you believe it’s more likely that the study would replicate than it would not replicate. Answers below 50 indicate that you believe it’s more likely that the study would not replicate than it would replicate. Intervals (the range between your lowest and highest estimate) which extend above and below 50 indicate that you believe there are reasons both for and against the study replicating.
Getting the most out of group discussion
Once you have submitted your Round 1 estimates, you will be returned to the platform home page, where the paper should now have the “Round 2” tag. If you click on the paper again, you will be able to view estimates and comments made by other participants in your group. If you are the first to complete your Round 1 assessment, only your results will show and you may have to check back later.
The group facilitator will organise a time for you to meet (e.g. via a video-conferencing tool) to directly discuss the paper and ask questions of each other. The Discussion phase is a key component of the IDEA protocol. It provides an opportunity to resolve differences in interpretation, and to share and examine the evidence.
In the interest of time and efficiency, the facilitator will focus the group discussion on those questions where opinions within the group diverged the most. However, the purpose of the discussion is not to reach a consensus, but to investigate the underlying reasons for these (divergent) estimates. By sharing information in this way, people can reconsider their judgements in light of any new evidence and/or diverging opinions, and the underlying reasons for those opinions.
Here are some tips and ground rules for the Discussion phase.
We encourage you to review others’ assessments and – in particular – examine any comments in response to Question 8: Credibility, because this is where assessors capture their thoughts and reasoning on the various dimensions of the paper’s credibility. You can <use the comments feature on the platform to react to other participants’ judgements, interrogate their reasoning, and ask questions.
Once again, it is important that you do not use any participant names in comments on the platform, not even your own. Comments will eventually be made public, and we need to keep these anonymous. If you want to refer to other participants, please use the anonymous user name (avatar) they have been assigned e.g. Koala11.
You will not be able to access and review the evidence-level questions in Round 2 until you have answered the Round 2 paper-level questions. For that reason, you may wish to enter some provisional Round 2 estimates in order to proceed to and review the evidence-level questions. You can always change your Round 2 estimates during/after the group discussion, up until the paper is formally closed for assessments by the repliCATS team.
Some ground rules for the Discussion phase, regardless of whether you are leaving comments on the online platform or discussing directly:
- Respect that the group is composed of a diversity of individuals;
- Consider all perspectives in the group. In synchronous discussion, allow an opportunity for everyone to speak;
- Don’t assume everyone has read the same papers or has your skills – explain your reasoning in plain language;
- If someone questions your reasons, they are usually trying to increase their own understanding. Try to provide simple and clear justifications;
- Try to be open-minded about new ideas and evidence.
The following list may be useful to consider when reviewing and commenting on judgements. You do not have to work through these systematically, but consider which may be relevant:
- What did people believe the claim being made was? Was the paper clear? Did everyone understand the information and terms in the same way? If interpretations of the central claim (or any claim) vary, instead of trying to resolve this, focus on discussing what that means for the credibility of the paper.
- Consider the range of estimates in the group and ask questions about extreme values. What would cause someone to provide a high/low estimate for this question?
- Very wide intervals suggest unconfident responses. Are these based on uncertainties of interpretation or are these participants aware of contradictory evidence?
- Very narrow intervals suggest very confident responses. Do those participants have extra information?
- It’s ok if you don’t have good evidence for your beliefs – please feel free to state this.
- If you have changed your mind since your Round 1 estimates it’s good to share this. Actively entertaining counterfactual evidence and beliefs improves your judgements.
- If you disagree with the group that is fine. Please state your true belief when completing Round 2 estimates. This represents the true uncertainty regarding the question, and it should be captured.
- Consider raising counterarguments, not to be a nuisance, but to make sure the group considers the full range of evidence.
- As a group, avoid getting bogged down in details that are not crucial to answering the questions, or in trying to resolve differences in interpretation. Focus on sharing your reasons, not on convincing others of specific question answers.
Updating assessments (Round 2)
You can go into Round 2 as soon as you have finished Round 1, to review what others have said about the paper and its claims. Based on that, you can start entering Round 2 judgements.
The live Discussion will provide additional opportunities to examine and clarify the reasons for the variation in judgements within your group. You can continue to update your Round 2 judgements as you and your group go through and discuss the paper. You can also come back to a paper after you’ve had some time to think about it. Claims will remain open for the duration of the workshop and – if needed – for a few extra days to allow final updates. Let the repliCATS team know if you might need some more time.
Whether or not you want to update your estimates is entirely up to you. In some instances, your views and opinions might not have shifted after discussion, but perhaps not. Either decision is absolutely fine and provides useful information. Make sure you hit the submit button to log your Round 2 estimates, even if your assessments have not changed. Remember, your Round 2 estimates are private judgements, just like your Round 1 estimates, so there is no need to worry about what others might do or think about your judgements, and whether or not you have changed your mind.
The repliCATS Code of Conduct
We encourage all reviewers to read and adhere to the repliCATS Code of Conduct: https://osf.io/a5ud4/